Qwen Image & Video Generator
Qwen is Alibaba’s AI model with text video and image capabilities.

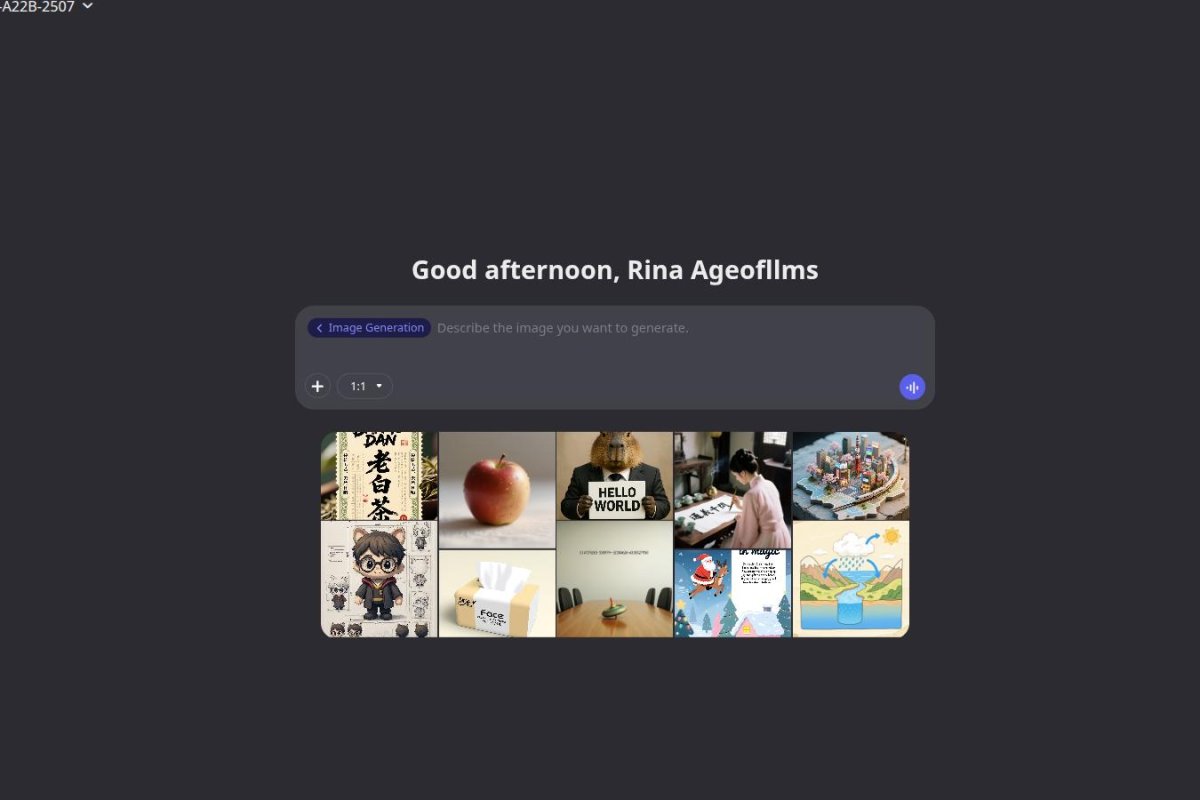
Overview
Qwen family of models are available on Alibaba Cloud’s Qwen Chat app and can be downloaded from Hugging Face for testing.
Developers can also integrate it through APIs. Pricing varies based on token usage with Qwen-Turbo being the cheapest option at $0.0004 per 1,000 input tokens.
The images are of decent quality with occasional hiccups like extra fingers, or legs.
Video generation is taking a while (several minutes, 10-20+ likely depending on their servers load) and typically fails the next time, with unknown timeframe needed to pass before you're able to generate your next one.
Images can be generated one after another, pretty much.
Qwen-Image is a free-to-use text-to-image model built by the team that also made the Qwen language models.
It uses Apache 2.0 license and packs in features like complex text placement, following prompts well, and editing stuff in pictures like adding or removing things or changing poses.
It also handles stuff like finding objects in an image, splitting them up, measuring depth, edge shapes, new view angles, and making things look sharper.
Image quality and how it handles text. People like how clearly it puts text into images, many saying it beats models like Flux and SDXL at that. But it’s not perfect. It slips a bit when the surface is bent or warped and sometimes looks kinda fake like it was pasted on.
Compared to other models. It’s better than WAN 2.2 and Flux at handling text and making skin look more natural. It also follows instructions more closely. WAN still leads when it comes to making super real-looking people in videos, but Qwen-Image stands out for how it handles language-based image generation.
Performance and hardware. The full model takes up around 40GB so it needs a graphics card with at least 24GB memory unless you shrink it down. You can shrink it using formats like GGUF or FP8, but quantizing too much, of course, makes the output worse.
It can run on regular computers too but it’s real slow there, like taking almost an hour for just one picture.
Censorship stuff. It’s mostly open with few limits. It can make adult images and even ones on hot-button topics like Tiananmen. Replicate might mark some outputs as not safe but won’t block them.
You can run it in ComfyUI, try on Hugging Face spaces or Qwen's online chat.
Tags
Freeware Apache License 2.0 PC-based #Image & GraphicsLinks
This tool offers the following AI models:
This list may not be exhaustive as new models keep dropping and are added to platforms all the time.
People are pumped that it’s fully open and pushing ahead with fewer limits. Some wonder how long that’ll last and what it means for teams like Meta or Mistral. Many like using regular sentences instead of tags to make pictures.
Image quality gets good feedback overall, but it’s not seen as a huge leap forward.
A bunch of users feel like image models haven’t really changed much since Flux dropped. Some say newer ones like Flux Krea or Qwen-Image are better at following prompts, but the output still looks kinda the same, like the same oversaturated, fake-feeling stuff. One user even called it Groundhog Day.
Qwen-Image got mentioned for doing comic panels and more consistent characters, but folks still seem to prefer the speed of older models like Flux Schnell. Krea can do things like pixel art, and some folks found ways to run it on GPUs with less than 8GB using Q4 quant versions.
Others say Qwen’s good at following prompts but struggles with output sharpness. Some fix that with sharpening tools. There's also complaints about Qwen and other models sticking too close to the same look no matter how the prompt is changed. It often misses stuff like camera angle or abstract ideas like “not a cat” or more layered scenes.
On top of that, the images can be fuzzy without post-processing. And while Qwen’s base model is decent, people are waiting on more fine-tuned models to really boost quality.
Overall, folks are split. Some say Qwen is solid and just needs polish, others feel like it's not keeping up with expectations. A few even said it looks like stuff made on Bing.
Source: [ Reddit ]
Generated on December 12, 2025:

Generated on November 15, 2025:

Generated on October 3, 2025:

Generated on September 17, 2025:

Generated on September 11, 2025:
Generated on August 26, 2025:

Generated on August 18, 2025:

Generated on August 7, 2025:

Generated on August 7, 2025:

Generated on February 3, 2025:
Generated on January 31, 2025:
Generated on January 31, 2025:
Generated on January 31, 2025:
Generated on January 31, 2025:
Generated on January 31, 2025:
Generated on January 30, 2025:

Generated on January 30, 2025:

Generated on January 30, 2025:

Generated on January 30, 2025:

Generated on January 30, 2025:

Latest Qwen Image & Video Generator News
November 17, 2025
Nunchaku’s pushing Qwen-Image-Edit fast. They’ve put out quantized versions of the 2509 model. The main thing is the pre-fused Lightning models with 4-step and 8-step edits.
It’s a good pick if you need fast image editing without using much VRAM.
September 23, 2025
Qwen-Image-Edit-2509 is out now. It lets you edit more than one image at once, with much better face and text consistency. It also works with built-in ControlNet. You can check it out in the Image Editing part of Qwen Chat.
August 21, 2025
Qwen-Image-Edit is now natively supported in ComfyUI. Click the template icon on sidebar → Browse Templates → Image → Qwen Image Edit.
August 18, 2025
Qwen-Image-Edit just launched.
Main features include:
Bilingual text editing. It supports both English and Chinese edits without messing up the style.
Content-level changes. You can rotate stuff or create new IPs.
Visual tweaks. Add, delete, or insert stuff in the image.
August 7, 2025
Qwen-Image - an image generation foundation model in the Qwen series is out under Apache 2.0 licence.
Useful Links
Nunchaku’s Quantized Versions of Qwen-Image-Edit
Version
Pre-fused Lightning models with 4-step and 8-step edits on limited VRAM.
White_to_Scene
LoRA
Built on Qwen-Image-Edit-2509, this Image Fusion tool lets you drop any object into a new scene smoothly. Just use the keyword “change white background to scene” and say what kind of scene you want.
Next Scene Qwen-Image LoRA
Version
A LoRA made to create image sequences that feel like they belong in a movie. It handles how the camera should move, how scenes should look, and makes sure shots connect well from one to the next.
Qwen-Image InstantX Inpainting ControlNet
Workflow
Qwen-Image InstantX Inpainting ControlNet is natively supported in ComfyUI
Boreal-Qwen-Image
Version
Qwen-Image Boring Reality - experimental LoRAs which help you create super reslistic images with Qwen
Qwen Image Edit Relight (Spaces)
Other
Try relighting images with Qwen Image Edit on HuggingFace Spaces
Qwen-Image-Lightning
Version
Qwen-Image has been distilled to run in 8-steps. You get nearly the same image quality, with >50% less compute required.
Qwen-Image ComfyUI Native Workflow Example
Workflow
After updating ComfyUI, you can find the workflow file in the templates, or drag the workflow below into ComfyUI to load it.
This page was last updated on November 17, 2025 at 7:42 AM