Stand-In
Stand-In is a lightweight identity-preserving video generation tool.
Overview
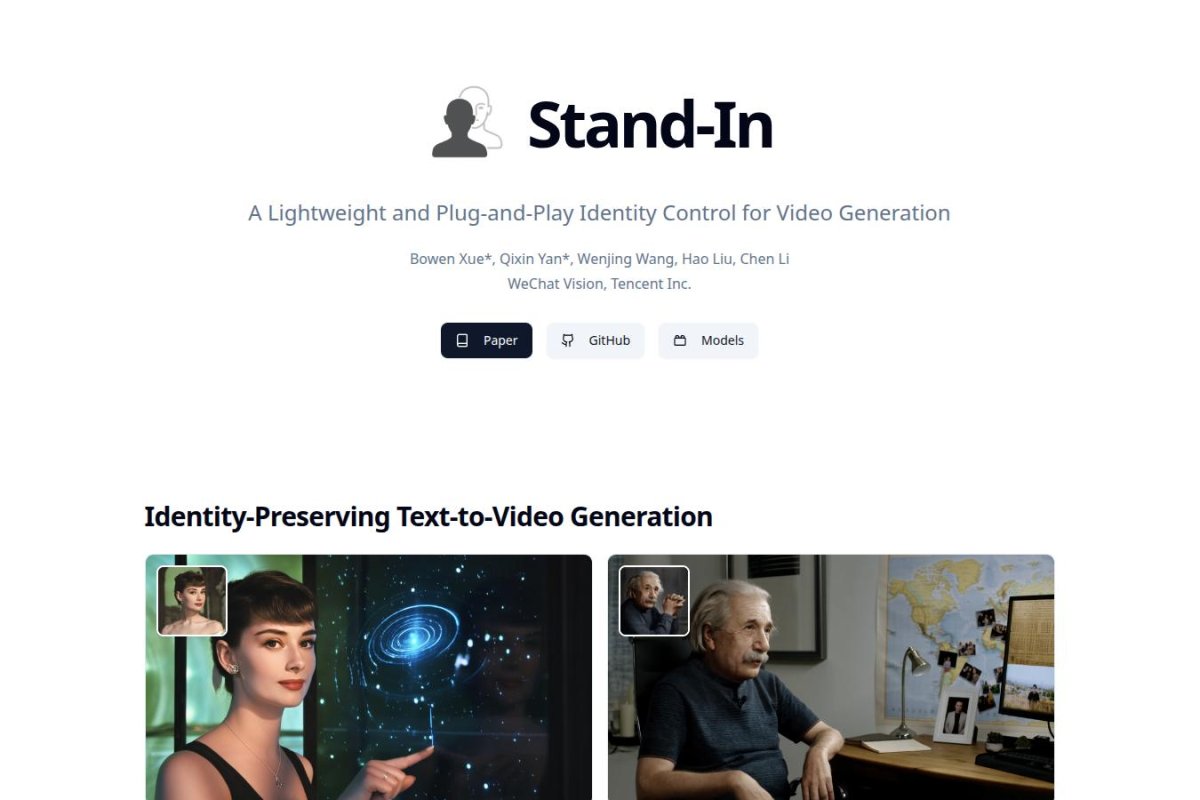
Stand-In is a plug-in for text-to-video models that keeps people looking like themselves in AI-made clips. It does this by retraining only about 1% of the system which makes it light and quick to run
The team behind it is Bowen Xue, Qixin Yan, Wenjing Wang, Hao Liu and Chen Li. They pushed it to GitHub on August 9 2025 along with the weights and inference code for their base Wan2.1-14B-T2V model
The trick is a conditional image branch added to the video generator. Instead of training the whole thing Stand-In uses limited self-attention and conditional positional mapping to bring in identity details from a reference picture. They trained with as few as 2000 image-video pairs
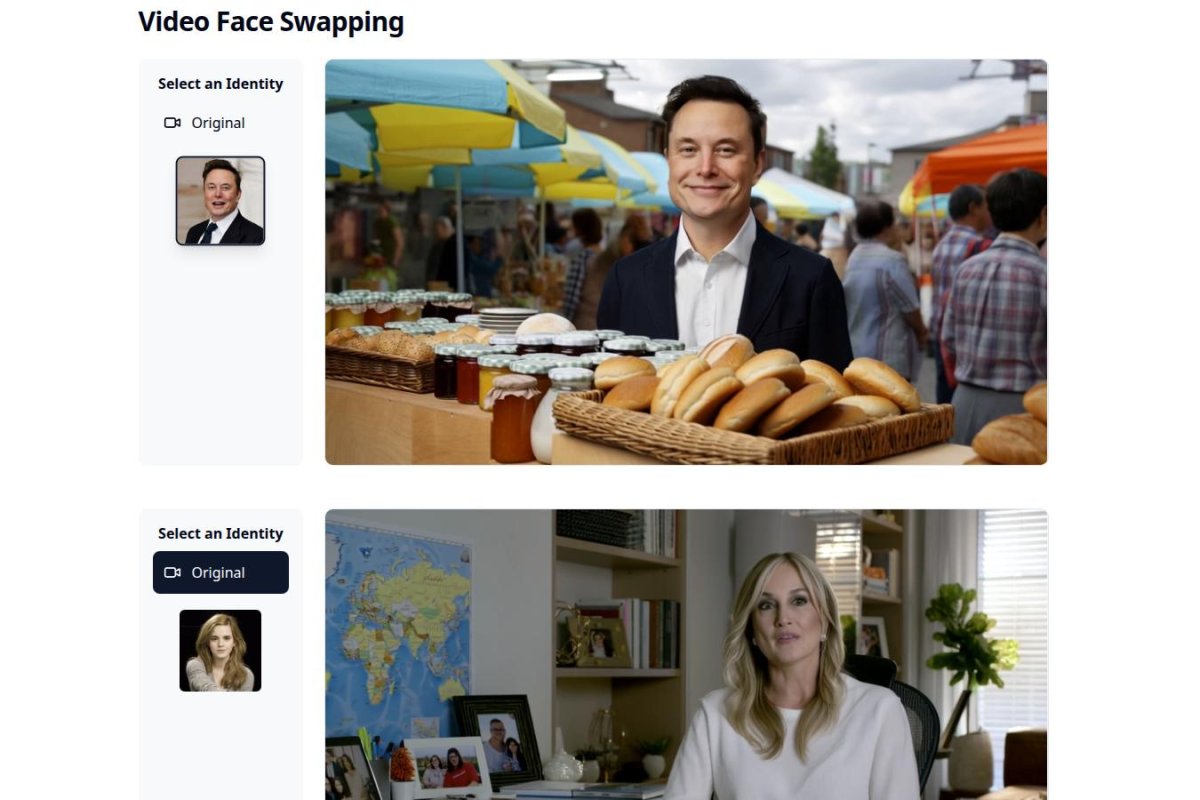
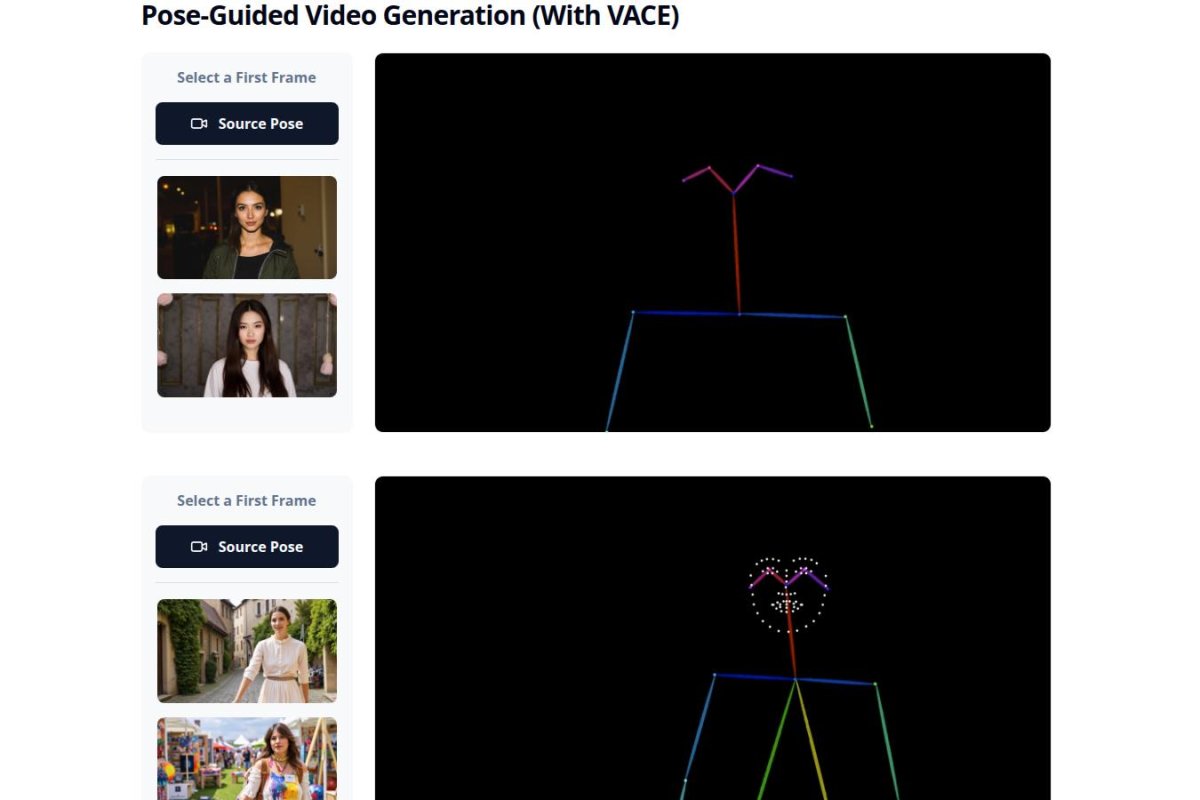
Even with such a small tweak it supposedly beats full retraining in both video quality and identity accuracy. And it’s easy to add on for other uses like subject-driven videos style changes pose-guided scenes and swapping faces.
Tags
Freeware Unknown License PC-based #Video & AnimationLinks
Useful Links
No additional links available for this tool.
This page was last updated on August 13, 2025 at 1:53 AM