This is an AI image generation comparison for
text-to-image  prompt:
prompt:
A painted woman, depicted in digital illustration style, her skin layered with visible brushstroke textures, stands perfectly centered in a realistic urban street, her posture quiet and composed. She holds a magenta umbrella, shielding herself from the soft rain that falls in streaks across the frame. Her face is turned slightly in profile, with the camera placed at eye level, using a symmetrical frontal composition, giving the scene a poised, contemplative stillness. Her hair transitions a...
Log in to see full prompt.

Tested: August 25, 2025
Kontext is not just for image editing, you can generate pretty awesome pictures in it too.

Tested: August 25, 2025

Tested: August 26, 2025

Tested: August 26, 2025

Tested: August 26, 2025

Tested: August 26, 2025
We can use Runway's reference model for simple image generation too.

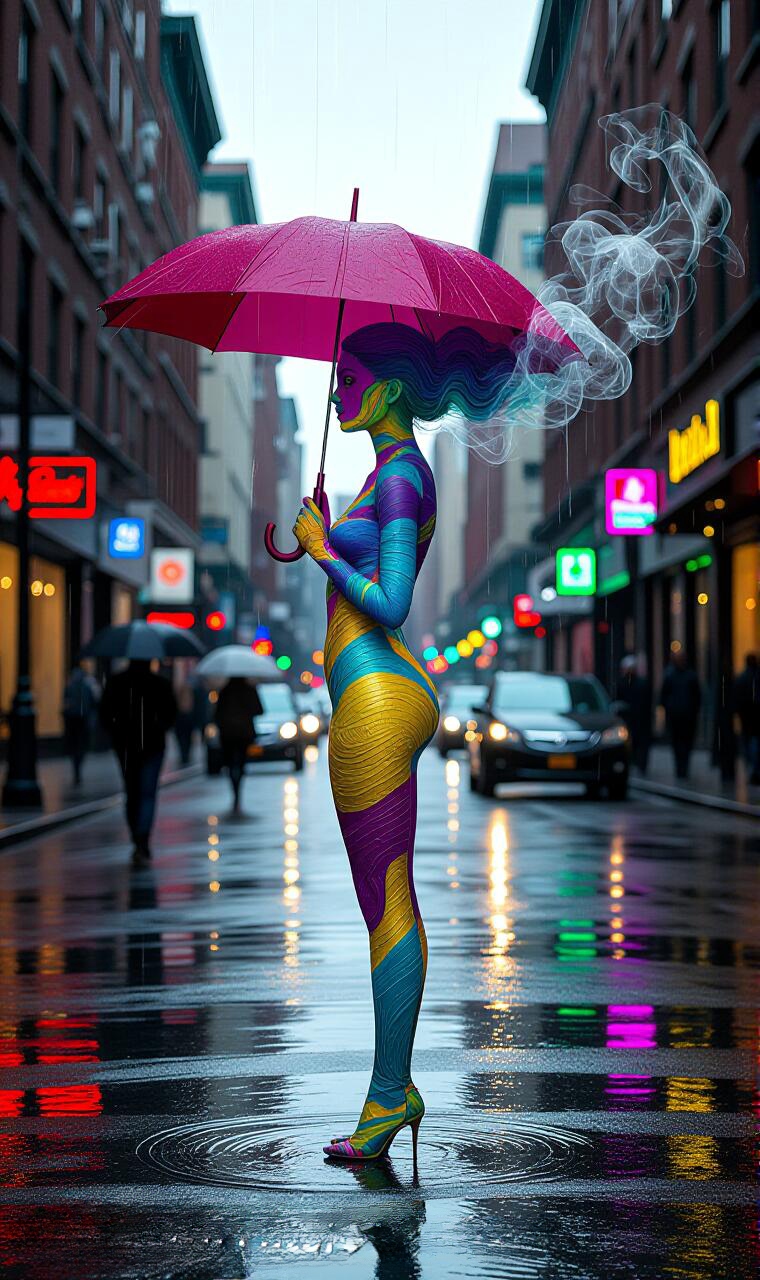
Tested: August 26, 2025
Quantized version in ComfyUI, using Q4 gguf

Tested: August 26, 2025
There was no room for the full prompt, made tightened version. Recraft V3 doesn't like long kontext prompts anyway, quality starts deteriorating the more details heavy the prompt gets

Tested: August 27, 2025
Looks similar to Imagen's result

Tested: September 10, 2025

Tested: October 27, 2025


Tested: November 25, 2025
Steps:18. Guidance: 6. Was just testing the JSON prompt with this lower number of steps but came out quite good already.
Is the woman’s figure clearly depicted in a painterly digital illustration style?
Are visible brushstroke textures present on her skin and clothing?
Does the woman appear perfectly centered in the frame with a symmetrical composition?
Is the background a photorealistic urban street scene with accurate detail (pavement, cars, storefronts)?
Is she holding a magenta umbrella that visibly shields her from the rain?
Are streaks of soft rain falling across the frame, interacting with the environment?
Is her face shown in slight profile with the camera at eye level?
Does her hair transition into wisps of smoke in turquoise, purple, and gold tones?
Does the smoke trail behind her subtly in slow motion, matching breeze movement?
Is the contrast between her surreal, painted texture and the realistic city clearly visible?
Are there crisp, grounded reflections in puddles (e.g., neon signs, bus, people)?
Check out the results from Black Forest Labs (FLUX) (FLUX Kontext [Max]) vs Magnific (Freepik) (Imagen 4 Ultra) vs Sora (GPT‑4o) vs Dreamina AI (Seedream 3.0) vs Kling AI (KOLORS) vs Magnific (Freepik) (Runway's Gen-4 Image) vs Qwen Image & Video Generator (Qwen-Image) vs HiDream-I1 (HiDream I1 Dev) vs Recraft (Recraft V3) vs Magnific (Freepik) (Google Nano Banana) vs Hugging Face (HunyuanImage 2.1) vs Comfy Cloud (FLUX.1 Krea [dev]) vs GROK (Grok Imagine v0.9 Image) vs Fal AI (FLUX.2 [flex]) for similar or identical prompts side-by-side.

Iridescent capybara handdrawn mixed media

Real guitarist with illustrated effects