F5-TTS
F5-TTS is transforming digital content access with powerful audio solutions that make everyday tasks, media, and interactive experiences more accessible and efficient. Whether in media, customer service, or learning, F5-TTS proves that voice-driven tools are both practical and highly effective.

Overview
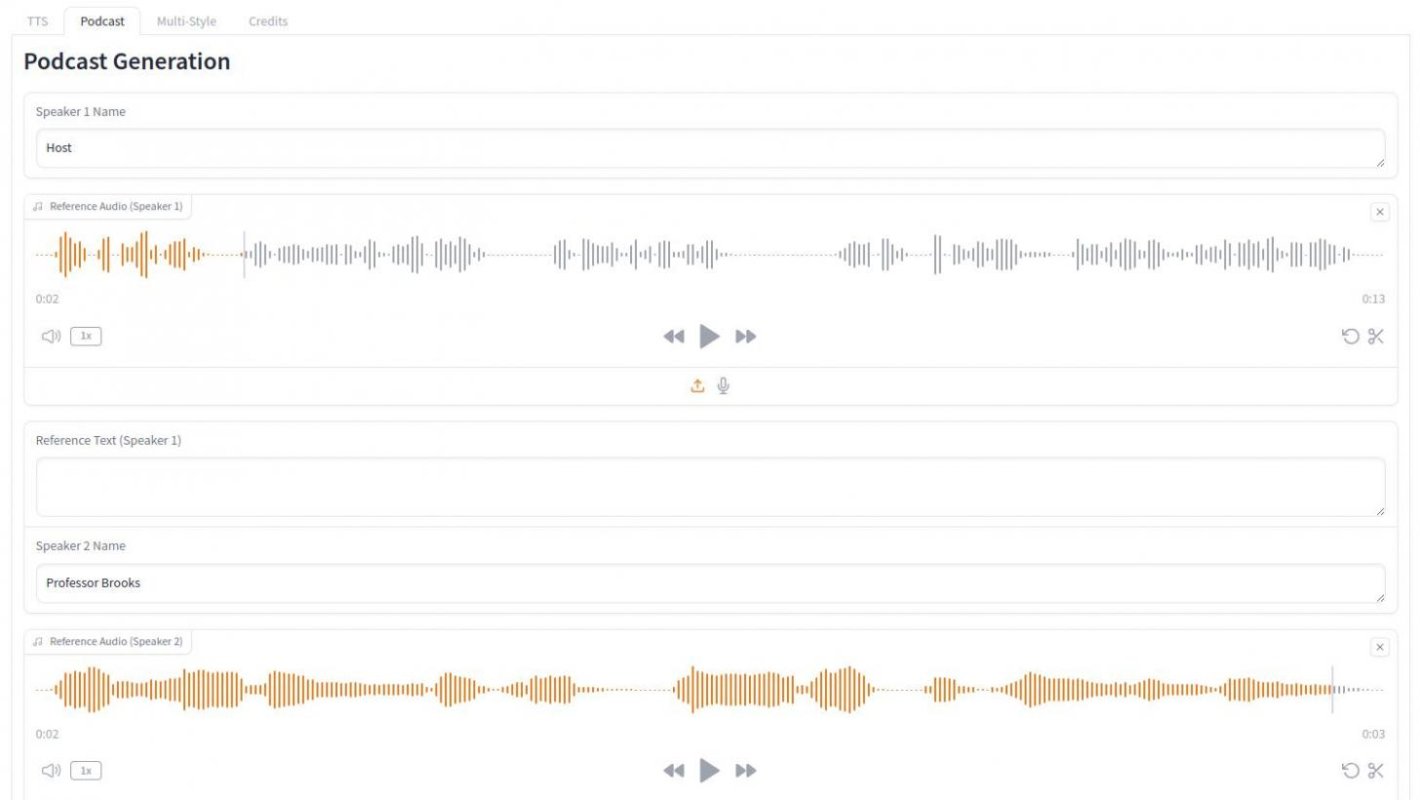
F5-TTS is an open source text-to-speech model which generates natural and expressive speech, by using sample audio of a few seconds, containing your own or somebody else's voice.
This advanced model with 335 million parameters handles English and Chinese voice synthesis, with more languages on the way. It’s trained on an enormous dataset of 95,000 hours and runs on 8 A100 GPUs, a process that took just over a week.
The performance is impressive, and big thanks to the developers for releasing it as free, open-source software. I’ve tested it with my own voice and some public-domain movie actors. The results are remarkable. F5-TTS and its earlier version, F2-TTS, both have their unique qualities: F2 has a more consistent tone, giving it a formal vibe, but F5 adds that lifelike spark.
Supported Languages
- Chinese
- English
- French
- Japanese
Tags
Freeware MIT License PC-based #Voice & AudioLinks
- Strengths:
- Expressiveness: Greater emotional range and better voice acting potential.
- Flexibility: Two variations (E2 model and others) cater to different needs.
- Weaknesses:
- Speed: Slower than xTTS-v2, especially for real-time use.
- Artifacts: Occasional issues at the start of the audio or with complex text.
- Setup Complexity: Harder to configure for first-time users.
[ Reddit ]
Generated on June 27, 2025:
Generated on January 18, 2025:
Generated on January 11, 2025:
Useful Links
ComfyUI node for F5-Text To Speech
Other
ComfyUI node to make text to speech audio with your own voice using F5-TTS
This page was last updated on June 25, 2025 at 11:26 PM